

Ideology Detection in the Indian Mass Media
Abstract
Ideological biases in the mass media can shape public opinion. In this study, we aim to understand ideological bias in the Indian mass media, in terms of the coverage it provides to statements made by prominent people on key economic and technology policies. We build an end-to-end system that starts with a news article and parses it to obtain statements made by people in the article; on these statements, we apply a Recursive Neural Network based model to detect whether the statements express an ideological bias or not. The system then classifies the stance of the non-neutral statements. For economic policies, we determine if the statements express a pro or anti slant about the policy, and for technology policies, we determine if the statements are positive or skeptical about technology. The proposed research method can be applied to other domains as well and can serve as a basis to contrast social media self-expression by prominent people with how the mass media portrays them.
Our full paper titled Ideology Detection in the Indian Mass Media has been accepted at International Conference on Advances in Social Networks Analysis and Mining (ASONAM-2020) and presented on 10th December, 2020 (virtual).
- The link to our full paper is available here.
- Zoom Recording of our full paper presentation at ASONAM-2020 is available here.
- Our conference presentation is available below.
- My Master’s thesis can be accessed as a preprint here.
Summary
I completed my Master’s Project under Prof. Aaditeshwar Seth at IIT Delhi. The project involved using machine learning to analyze the Indian mass media since there is a lack of computational frameworks for public policy analyses at present. How media ownership influences its bias, whether social media helps level mass media bias or amplifies echo chambers, are aspects that if understood by citizens can help strengthen the democratic frameworks to make the world a better place for everybody. We study four main policy events that have happened over the last few years - Aadhar, Demonetisation, GST and Farmers’ protests, to understand how certain aspects of these policies or certain entities involved in these policies were covered by various newspapers, and build a comprehensive framework to estimate coverage and sentiment bias in the media.
During this project, we built a web crawler to extract news articles related to these four ICTD policies using keyword matching and parse data from these articles to build a dataset of by-statements. It involves identification of the statements made by different entities and disambiguating people referred to by the same name and merging entities which are the same but referred to by different names. We first used OpenCalais for Entity resolution; while it gave correct results in the case of location-based entities, it is inaccurate for Person entities and hence, we built our own algorithm for resolving them. We keep two collections of entities - resolved and unresolved. For each unresolved entity, we query top ten matching entities in the resolved collection by fuzzy aliases matching using ElasticSearch and find the best match (with a slightly different algorithm), and if no match is found, the entity itself is added to the resolved collection. In-house annotation of the dataset was done by people in our research group, where each statement was labelled as pro, anti or neutral w.r.t. the policy.
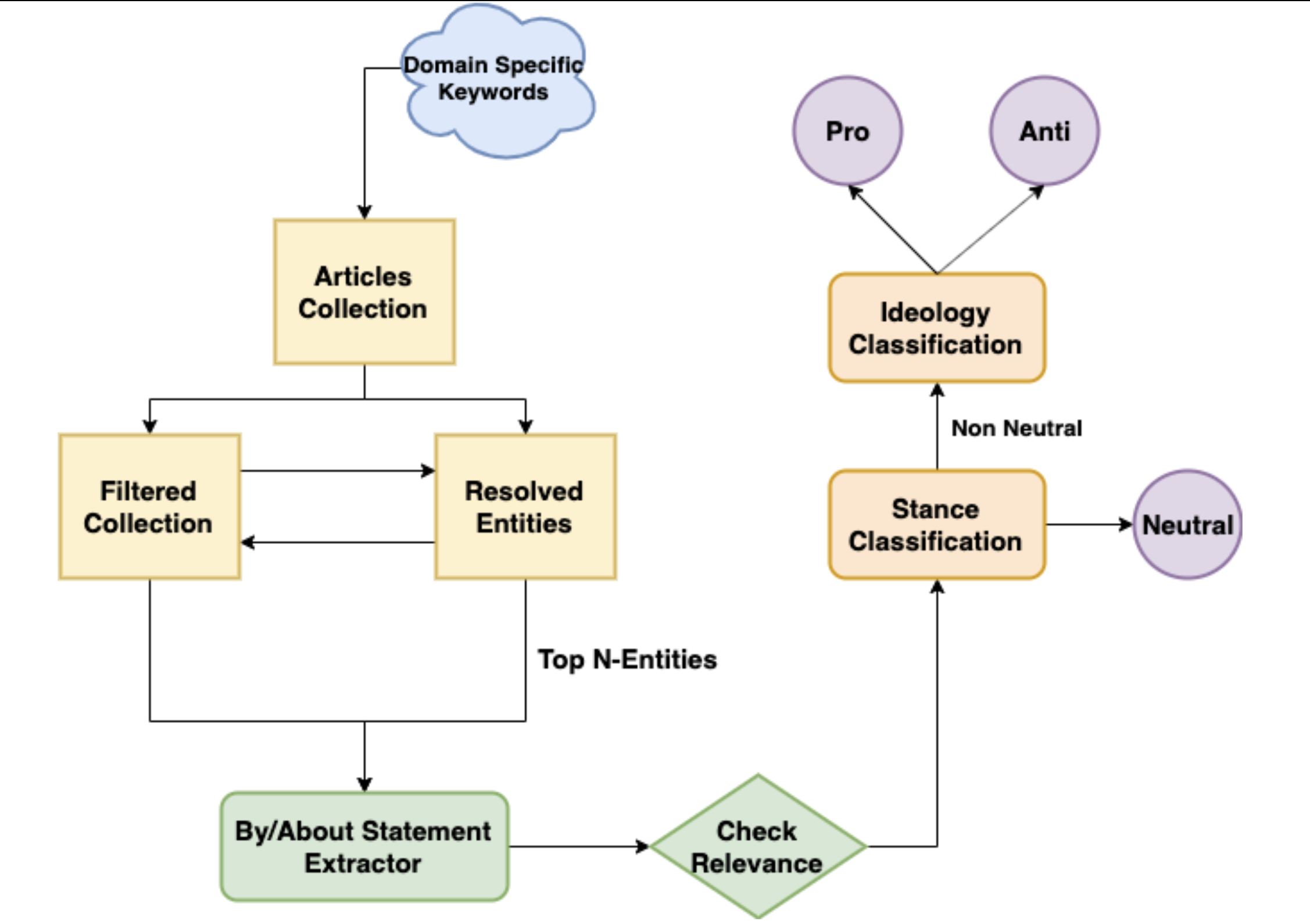
We found out that not all the statements which got extracted were relevant. Hence, our next task was to filter out these statements. Almost all of these statements contained some policy-related keyword which is why we could not use a keyword-based approach for checking non-relevant sentences. Thus, we used two layers of filters - (i) dependency-tree based approach which checks if the subject and object phrase of a statement is related to the policy, and (ii) semi-supervised approach where we used LDA with collapsed Gibbs Sampling, which can be guided by setting some seed words per topic making the topics converge in a particular direction.
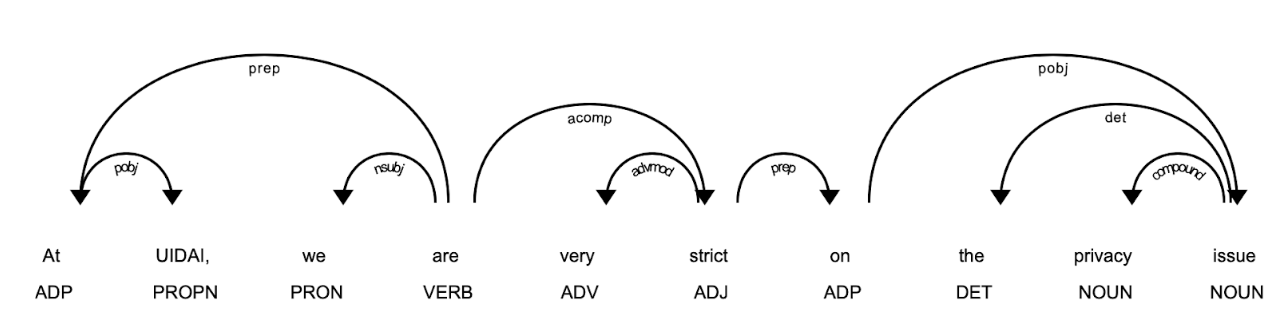
Building a classifier for stance detection was the most challenging task. It is difficult to predict the overall sentiment when the stance changes within a sentence and we wanted a classifier that could generalise well to new policies. We also wanted the results to be interpretable so that the results would be credible. Moreover, the dataset was small-sized and unbalanced for most of the policies, with almost 70% of the statements being pro-policy. Hence, we focused on using small capacity models to avoid overfitting. We tried out a network inspired by recursive NNs (Iyyer et al., 2014) and Tree LSTMs (Tai et al., 2015) for this task, with minimal layers. The performance of the model was found to be decent despite the small size of the dataset. To further improve the performance, we explored using word2vec (Mikolov et al., 2013) embeddings, pre-trained on the Google News corpus, which increased the accuracy slightly. We then fine-tuned the word2vec embeddings on policy-related news articles and noticed that the accuracy jumped up by 6%. Although a significant increase, on interpreting the results, we found out that the embeddings learnt were highly biased and always resulted in positive predictions if a given sentence contained the name of an entity who always made pro-policy statements and similarly for negative statements. We also noticed that irrespective of a statement being clearly anti-policy, the presence of a policy supporting entity in the sentence led to pro policy predictions. On visualising the embeddings through a t-SNE plot, we found out that a number of separate clusters were formed, with the most dense ones being the one which contained only Muslim entities, while another one which had right-wing politicians. To mitigate this bias, we blacked out all the Person entities in the corpus and then fine-tuned word2vec on it. It resulted in a slight increase as compared to using the pre-trained embeddings. Next, taking inspiration from ELMo (Peters et al., 2018), we trained a bidirectional language model on our policy-related news articles collection, with blacked-out person entities and added this to our classifier. This resulted in significant performance improvement. We have not yet experimented with more sophisticated NLP techniques like using the attention mechanism or a transformer since the size of our dataset is small; we also wanted to reduce dependence on computing power, so that such an analysis could be replicated at various places without many computational requirements.
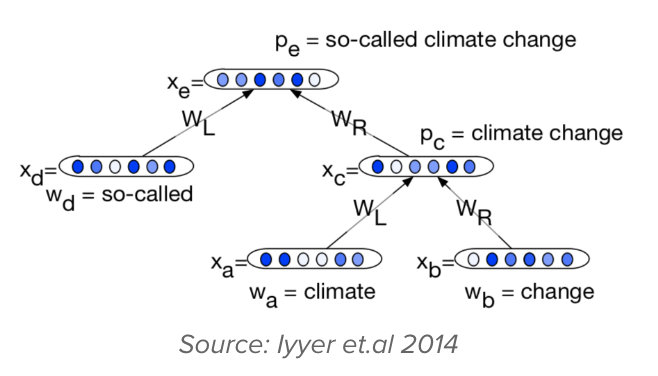
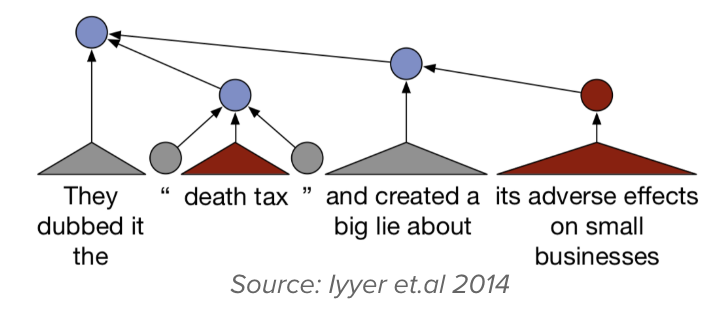
Future directions that we want to explore is further performance improvement by explaining the predictions of our classifier and increasing interpretability of the results. LIME (Ribeiro et al., 2016) seems like a promising technique we could consider. We are also working towards increasing the dataset size. This project will go on until I graduate; it has been a great experience so far and we hope to publish in early 2020. The project has convinced me that I will enjoy working on applicative machine learning in a research setting.