
AlphaZero for the Game of Go
Objective
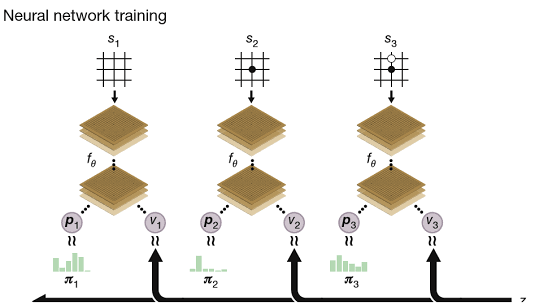
The following project implements the game of Go on a board size of 13x13 with the Chinese set of Rules and Komi value of 7.5. Details of these rules can be found here. Our implementation is based the AlphaGoZero paper Silver et al., 2017 by DeepMind. As described in the paper, we use MCTS with a single neural network that gives policy and value predictions with a self-play based adversary strategy to learn how to play.
Implementation Details (Github Link)
- Representation of State: Since the current 13x13 matrix of board position is not sufficient to determine a state, we use past 5 board positions of the current and the opposite player along with the color of the current player to determine the state. Therefore, the state is represented by a tensor of shape 11x13x13. The policy is represented by a vector of size 171x1 as there are 13x13 actions on the board, plus 2 for pass and resign actions.
- Episodes from MCTS: All the code has been implemented from scratch. The (x,y) coordinates of each stone on the board are used to represent board positions since no images are used. Using MCTS, the agent plays with itself until 100 simulations. MCTS can be viewed as a self-play algorithm that computes a vector of search probabilities for each state s recommending moves to play \(\pi = \alpha_{\theta}(s)\), which is proportional to exponential visit count for each move, \(\pi_{a} \propto N(s, a)^{1/\tau}\) , where \(\tau\) is the temperature parameter. Initially, the temperature is set to 1.0. After training for ten episodes, we set the temperature to 0.4. At each time step, an action is selected in MCTS according to:
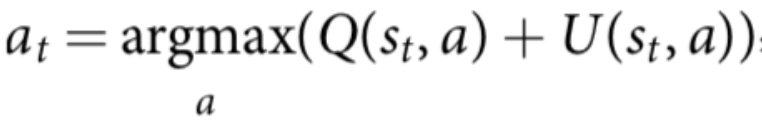 , where
, where
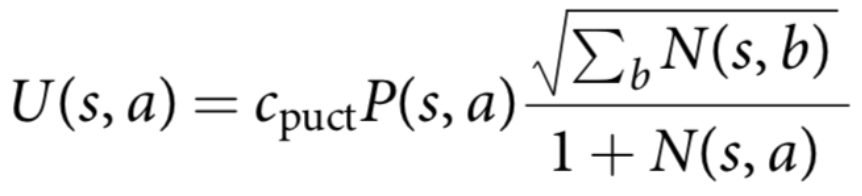
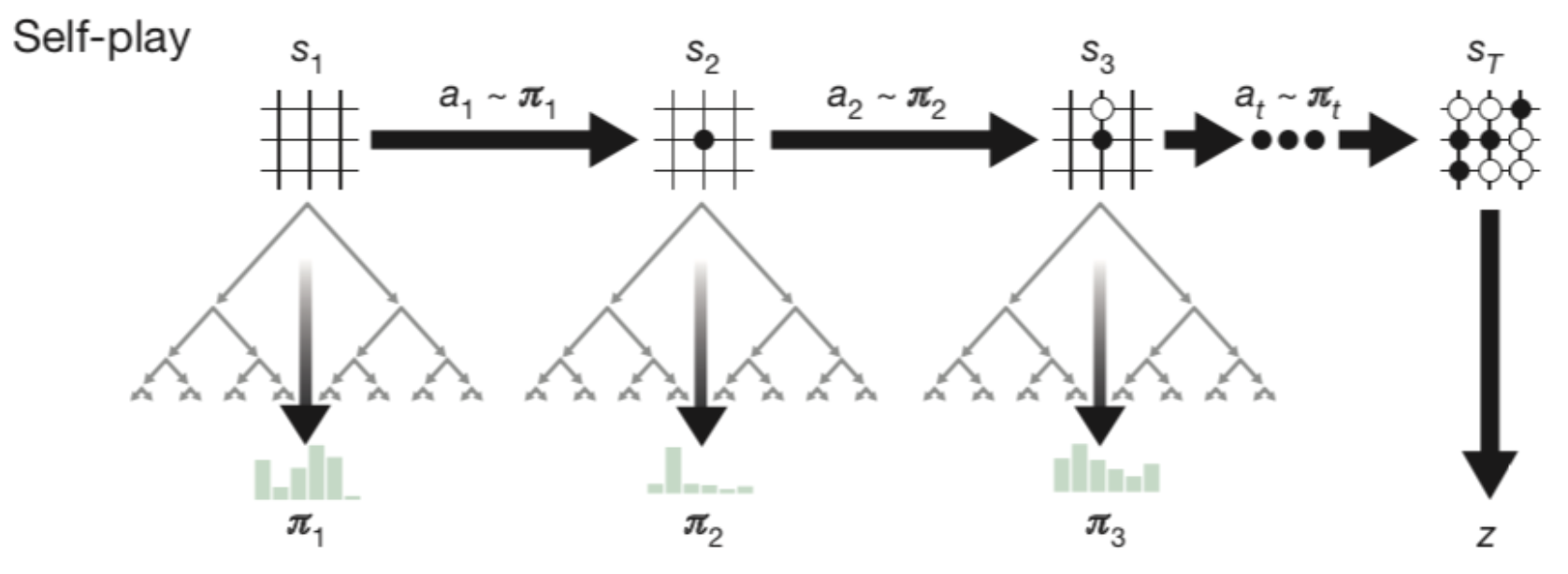
We used the pachi-py simulator to model the dynamics of the environment. The agent can carry out multiple simulations starting from the same state in the copy of a simulator to propagate the value up the search path. This way more the number of simulations of MCTS, better are the decision choices.
- Policy Value Network: We tried several architecture tweaks like changing the order of layers, number of convolutions, types of pooling, use of regularizers like dropout and batch normalisation. We have reported the architecture which gave the best accuracy. To give a brief, this network combines the role of policy and value network into a single architecture. It consists of a convolutional layer followed by 10 residual blocks of 2D convolutional layers with batch-norm and ReLu activation. The output of this is fed to two heads - policy head and value head. While the policy head consists of a convolutional layer followed by a fully connected layer that outputs a distribution over legal actions, the value head consists of a convolutional layer followed by two fully connected layers and tanh activation. All the convolutional layers are followed by batch-norm layers. The output of the value head is a positive or negative scalar value depending on whether the black or white player wins.
The loss function used for optimisation consists summation of (i) the Value Loss, a MSE loss between value predicted by network and the reward at the end of the episode, and (ii) the Policy Loss, a cross-entropy loss between the policy predicted by network and that given by MCTS. Stochastic Gradient Descent with momentum is used for training. L2-regularisation was used for all the parameters of the network.
We rotate the board by \(90^{\circ}\), \(180^{\circ}\), \(270^{\circ}\) anticlockwise and flip it horizontally and vertically for data augmentation. Since these board positions are equivalent, this ensures robustness in our model and allows us to train for these states as well without having seen these states before.
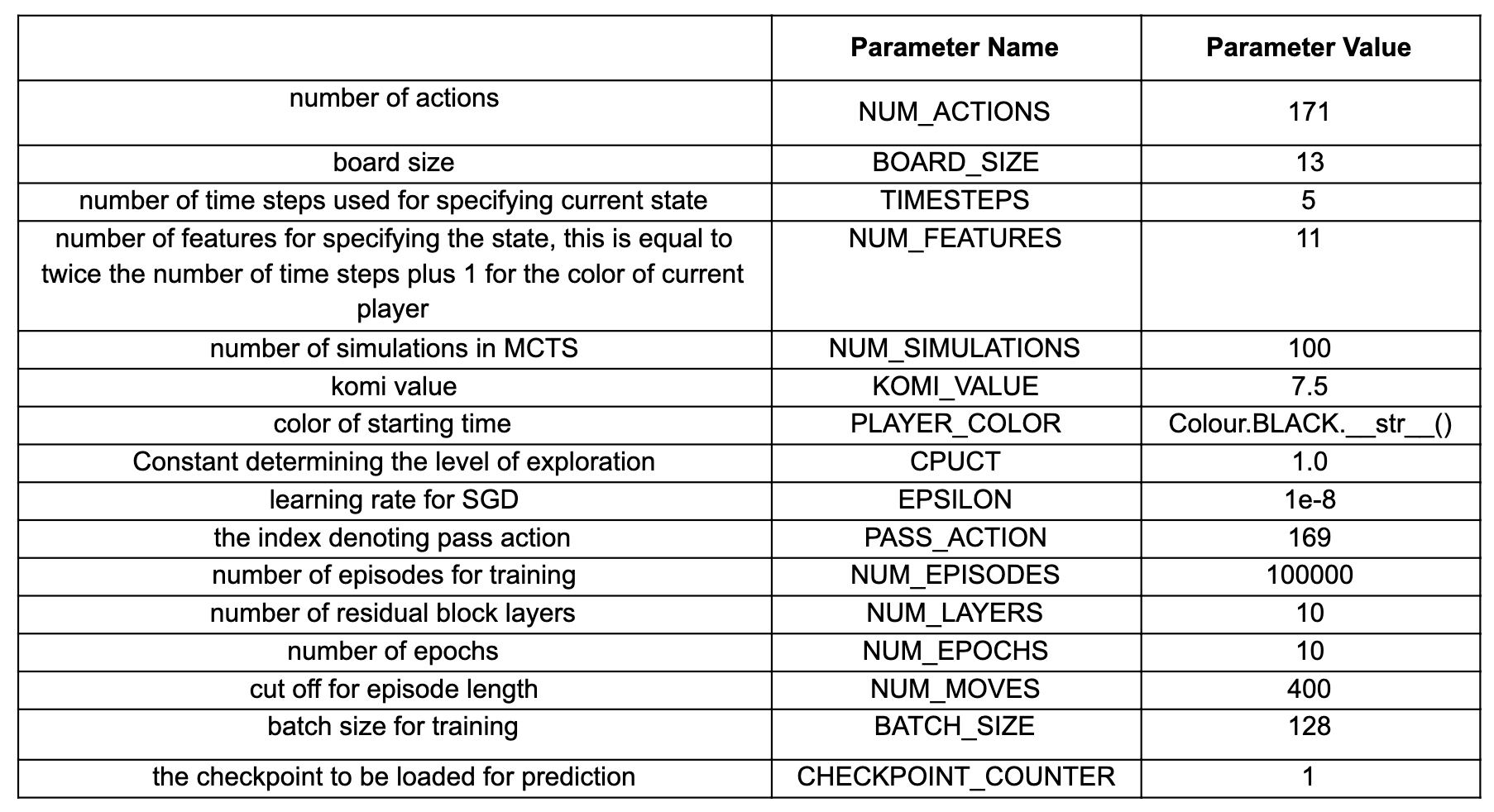
- Parameters: The following table gives a detailed list of all the parameters used in the project. These are specified in the
config.pyfile.
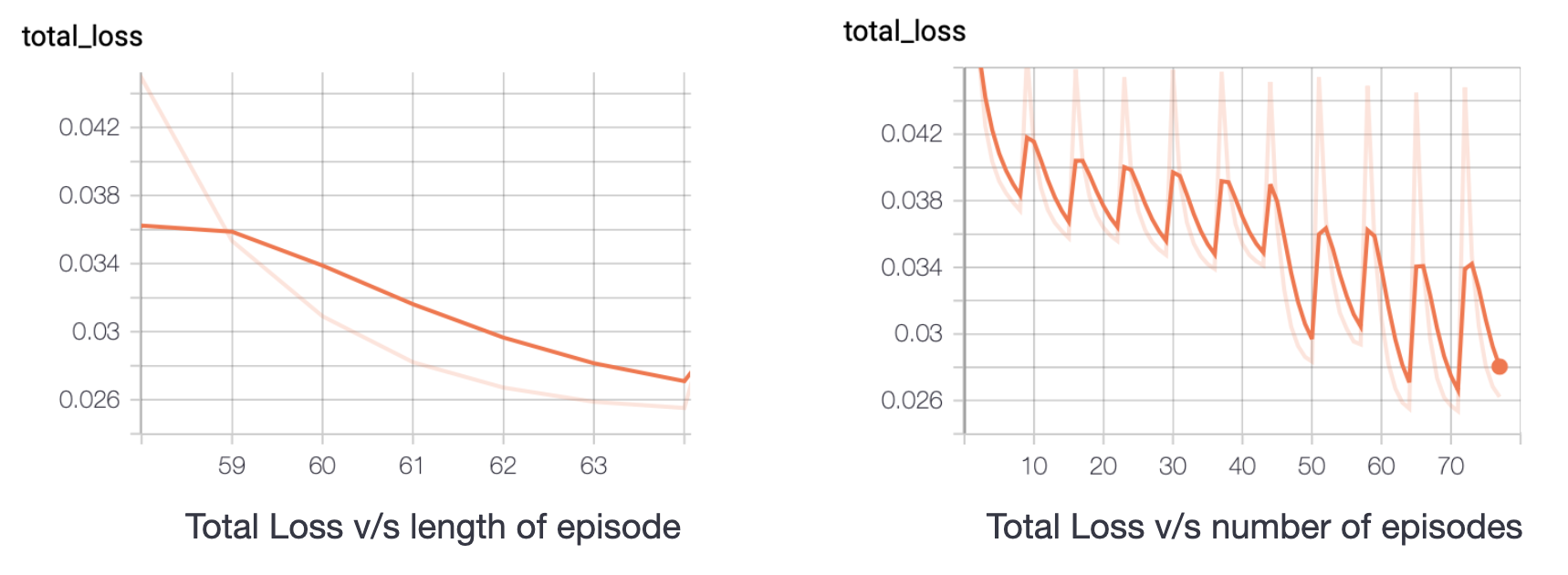
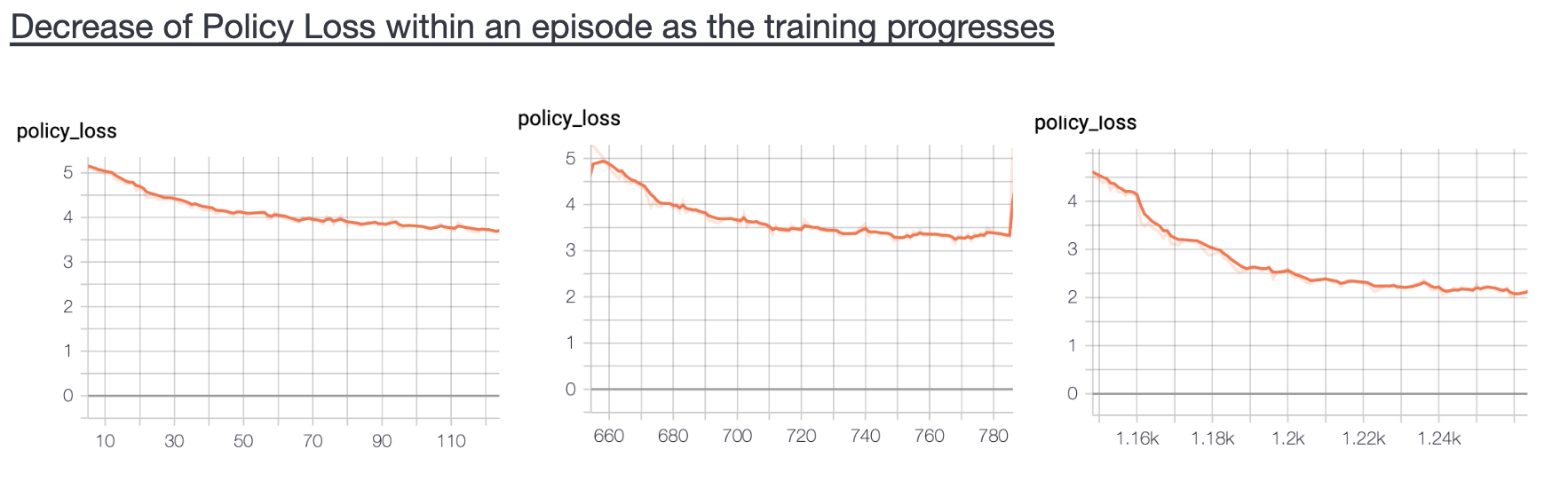
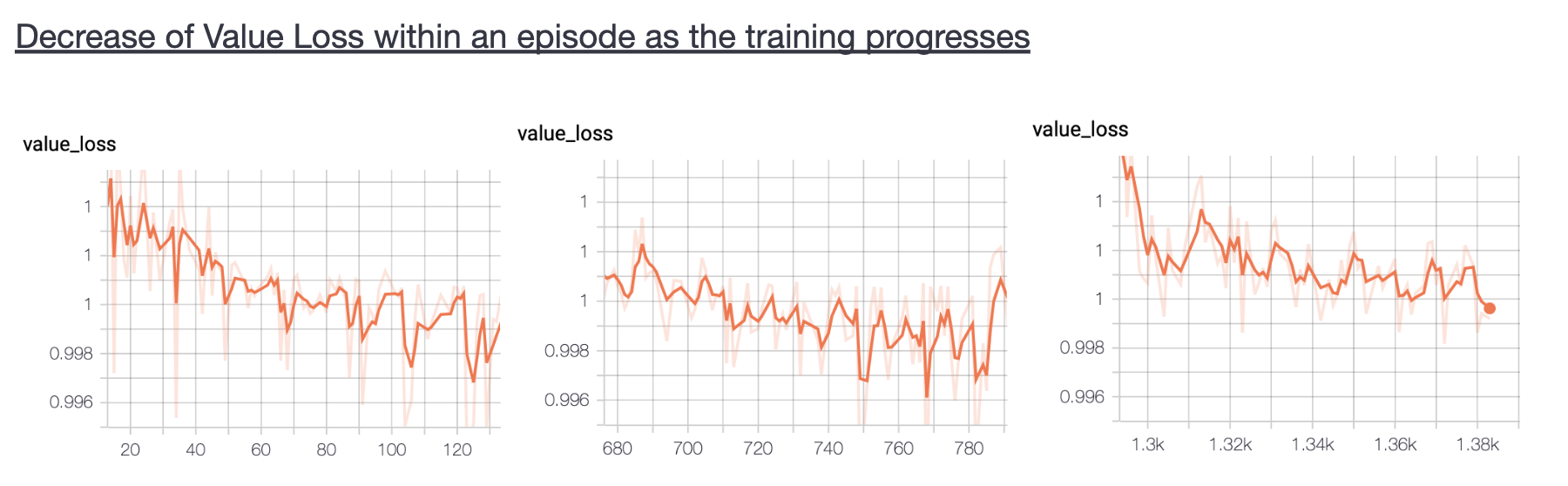
- Observations: The following graphs show the variation of loss as one episode progresses and with increasing number of episodes. It can be noticed that although the total value loss fluctuates and does not continuously decrease, the overall loss and total policy loss continuously decrease. The fluctuations in total value loss are not of big concern since the scalar value of loss itself is very small, of the order \(10^{-3}\).
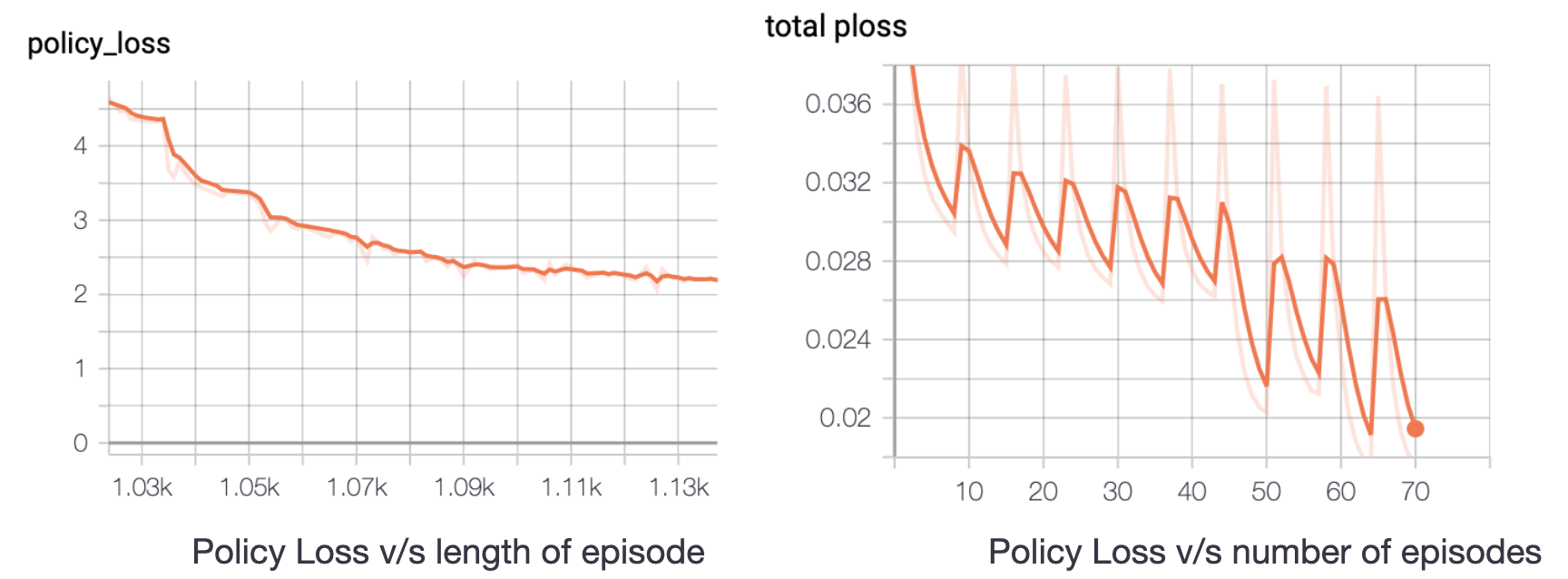
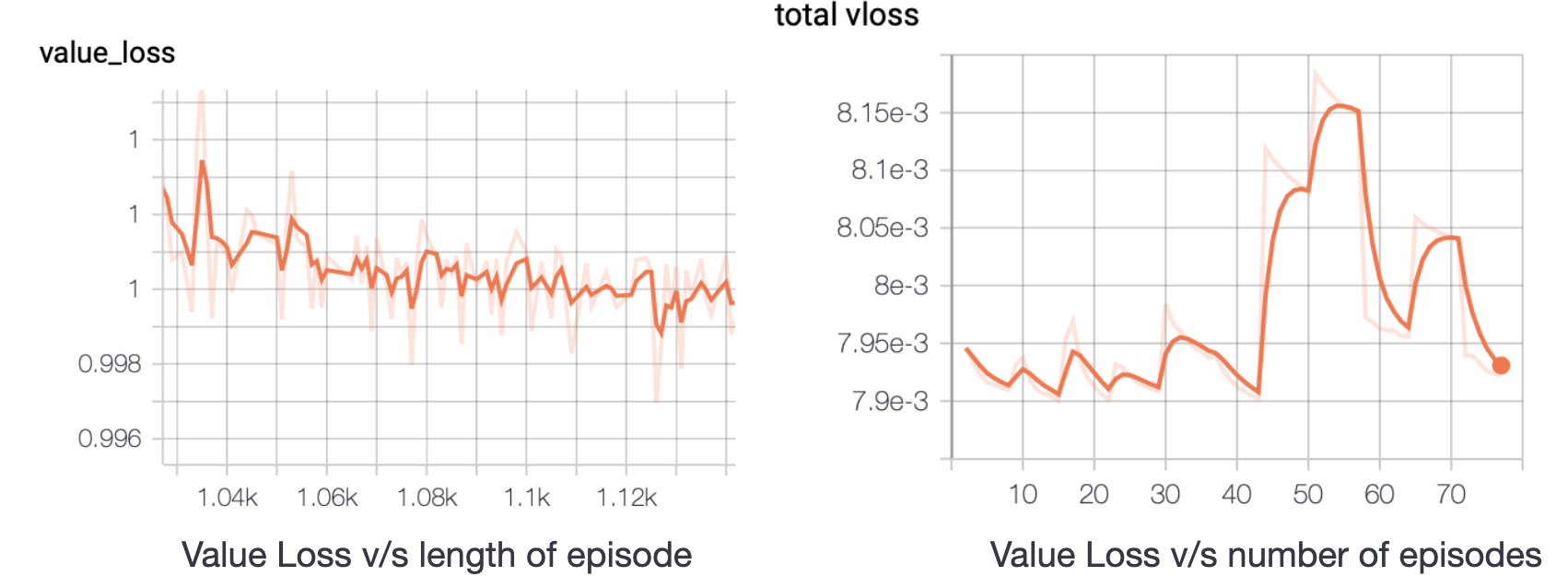
Below are shown some figures that show how policy and value loss decrease within an episode as training progresses. We can notice that the rate of decrease of loss increases with more number of episodes whereas the same decreases for the value loss. The value loss remains in the range 0.990-1.00 during the whole training process.
- Challenges Faced:
- Infinite Episode Length
- Passing State to Functions (issues with copying)
- Determining Legal Moves
- Issues in Running MCTS
- Large Training and Prediction Time
- Difficulty in Hyperparameter Tuning due to large training time.
- After training our model on 5 episodes with 10 simulations of MCTS, we found out that the random policy was still performing better than the trained model. We made the following changes to deal with this problem:
- We increased the number of simulations from 20 to 100. This allows our agent to make optimal choices by providing it good training examples to learn from.
- To decrease the prediction time within boundary range of 5 seconds, we decreased the number of timesteps which are being fed to the network while ensuring a complex enough network with an adequate capacity to learn.
- Usage Instructions: Our source code consists of the following files inside the utils_6 folder.
policyValueNet.py: Architecture and training procedure for the neural networkMCTS.py: Gives policy for a given state after running MCTS for 100 simulations.selfPlay.py: Starts training the model after loading the latest checkpointutils.py: Contains helper functions to be used for MCTS & Policy-Value Networkconfig.py: Parameters required for the configurationenums.py: Enumeration class for BLACK & WHITE colours
To install the dependencies of this project, run
pip install -r requirements.txtTo download the model in
model_6foldersh download_model_6.shTo start the train (best checkpoint will be automatically loaded)
sh train.shTo start playing with AlphaGoPlayer_6.py against a random/fixed agent, execute
python tournament.pyTo visualise the decrement in the loss of policy & value (inside the utils_6 folder)
tensorboard logdirs='./logs' --port=6006
Other results have been mentioned in this link along with a comprehensive report.