Camera-based Music Player Control
Objective
The task in this assignment is to identify the direction of the gesture made by a user in front of the camera. We will limit the gestures to next, previous and stop signs as shown in the figure below. So, the model would predict one of four classes - Previous, Next, Stop and Background/Others.
Brief Description of the approach followed
-
Creating Dataset
- We record videos using multiple cameras, in multiple exposure settings. Both the assignment partners repeat this process for the 2 kinds of datasets - a) with a plain background, and b) with a generic background.
- Plain Background: We record videos using multiple cameras, in multiple exposure settings. Both the assignment partners repeat this process for the 2 kinds of datasets - a) with a plain background, and b) with a generic background.
- Generic Background:We record in front of a noisy but static background. This time we make 3 classes - right, left and stop with again 4000 frames sampled total for each class. If a new image has scores for all three classes below a threshold, it is labeled ‘none’. Also, again our right and left labels are inverted because of inversion in the camera. They are with respect to the person doing gestures.

- We record videos using multiple cameras, in multiple exposure settings. Both the assignment partners repeat this process for the 2 kinds of datasets - a) with a plain background, and b) with a generic background.
-
Data Pre-Processing & Augmentation
- We first resize the image to 50x50.
- Then we add flipped images for the left to right and vice versa.
- We also perform standard image augmentation techniques like zooming in-out, shearing, rotation, flipping, feature normalization, background substraction, etc. to make a more diverse dataset.
- Used the ensemble of models for prediction
-
CNN Model Architecture
- We used Skip connections to properly accumulate & backpropagate the gradients. Architecture can be seen below.
def model():
inputX = Input(shape = (50,50,3)) # resized images
X = Conv2D(96, (3, 3), name = 'conv0', padding = 'same', kernel_initializer = he_uniform(seed = 0))(inputX)
X = BatchNormalization(axis = -1)(X)
X = Activation('relu')(X)
X = Conv2D(128, (3, 3), name = 'conv1', padding = 'same', kernel_initializer = he_uniform(seed = 1))(X)
X = BatchNormalization(axis = -1)(X)
X = Activation('relu')(X)
X = MaxPooling2D(pool_size = (2, 2), padding = 'same')(X)
X1 = Conv2D(128, (3, 3), name = 'conv2', padding = 'same', kernel_initializer = he_uniform(seed = 2))(X)
X1 = BatchNormalization(axis = -1)(X1)
X1 = Activation('relu')(X1)
X1 = Conv2D(128, (3, 3), name = 'conv3', padding = 'same', kernel_initializer = he_uniform(seed = 3))(X1)
X1 = BatchNormalization(axis = -1)(X1)
X_mid1 = Add()([X, X1]) # Using skip connections
X_mid1 = Activation('relu')(X_mid1)
X2 = Conv2D(160, (3, 3), name = 'conv4', padding = 'same', kernel_initializer = he_uniform(seed = 4))(X_mid1)
X2 = BatchNormalization(axis = -1)(X2)
X2 = Activation('relu')(X2)
X2 = Conv2D(128, (3, 3), name = 'conv5', padding = 'same', kernel_initializer = he_uniform(seed = 5))(X2)
X2 = BatchNormalization(axis = -1)(X2)
X_mid2 = Activation('relu')(X2)
X_mid2 = MaxPooling2D(pool_size = (2,2), padding = 'same')(X_mid2)
X_mid2 = Dropout(0.2)(X_mid2)
X3 = Flatten()(X_mid2)
X3 = Dense(1024, name = 'fc1', kernel_initializer = he_uniform(seed = 6))(X3)
X3 = BatchNormalization()(X3)
X3 = Activation('relu')(X3)
X3 = Dropout(0.2)(X3)
# 4 classes -> no_hand, left, stop, right
X_final = Dense(4, activation = 'softmax', name = 'out', kernel_initializer = he_uniform(seed = 7))(X3)
model = Model(inputs = inputX, outputs = X_final, name = 'cnn3')
model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy'])
return model
-
Training
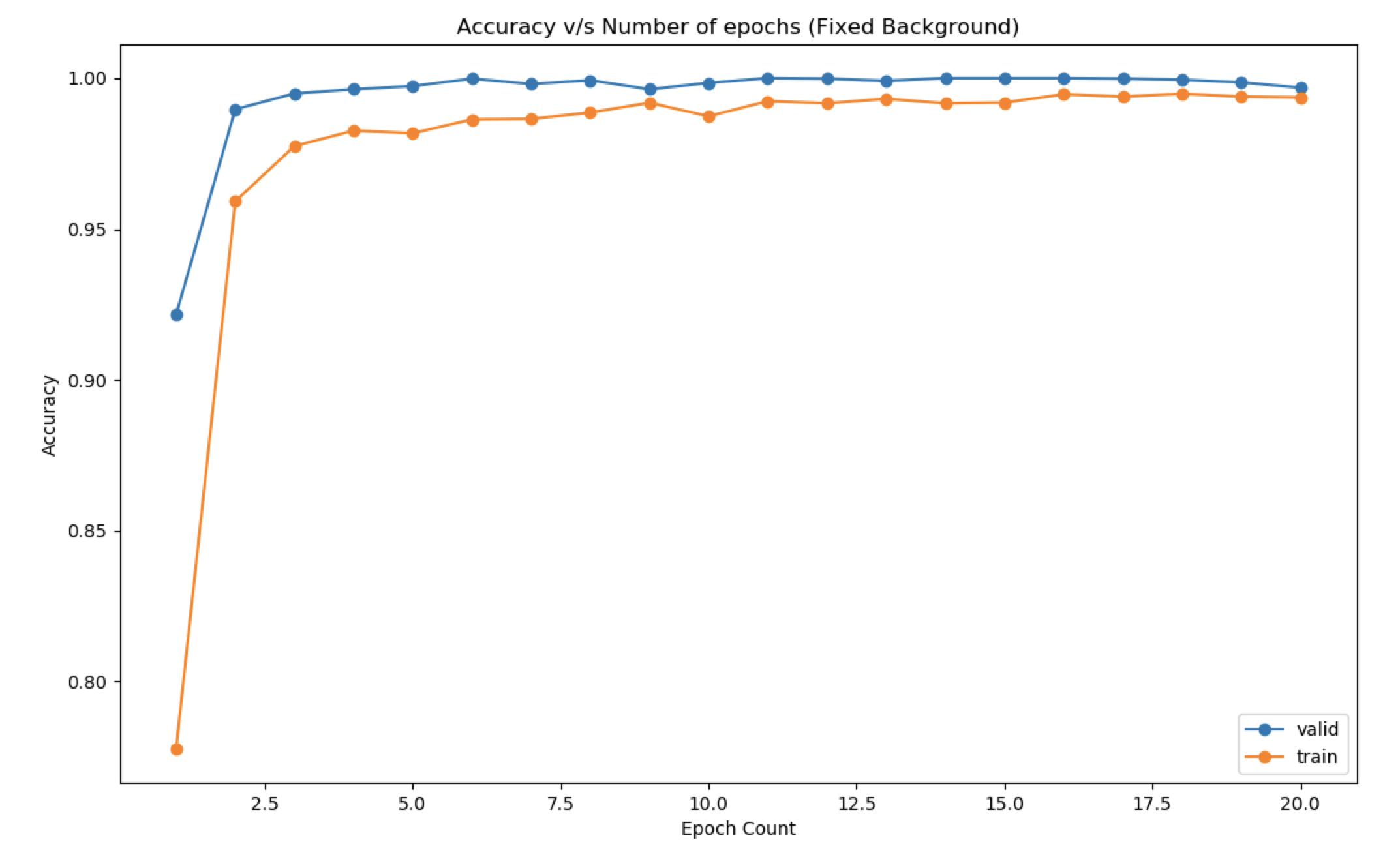
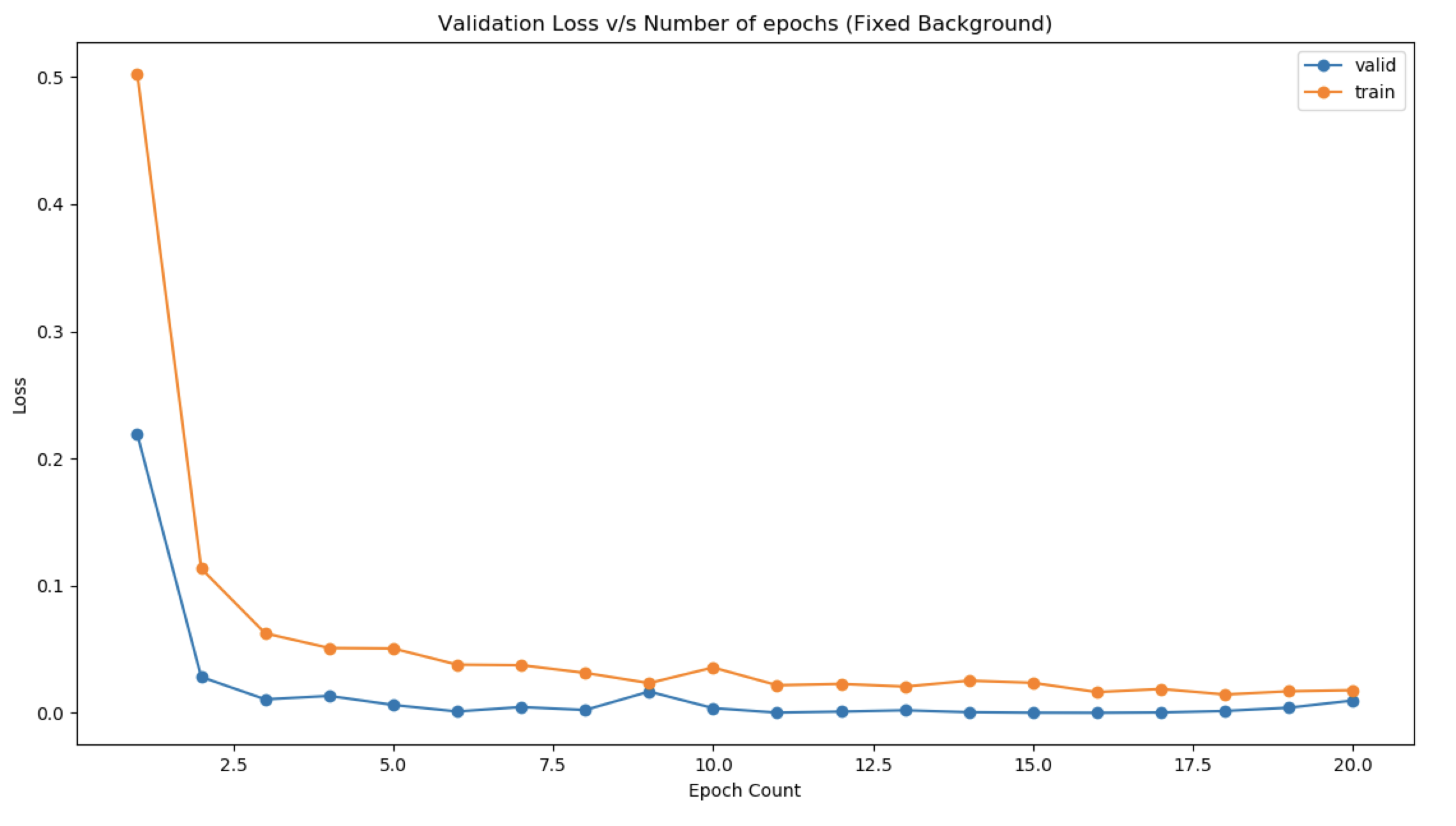
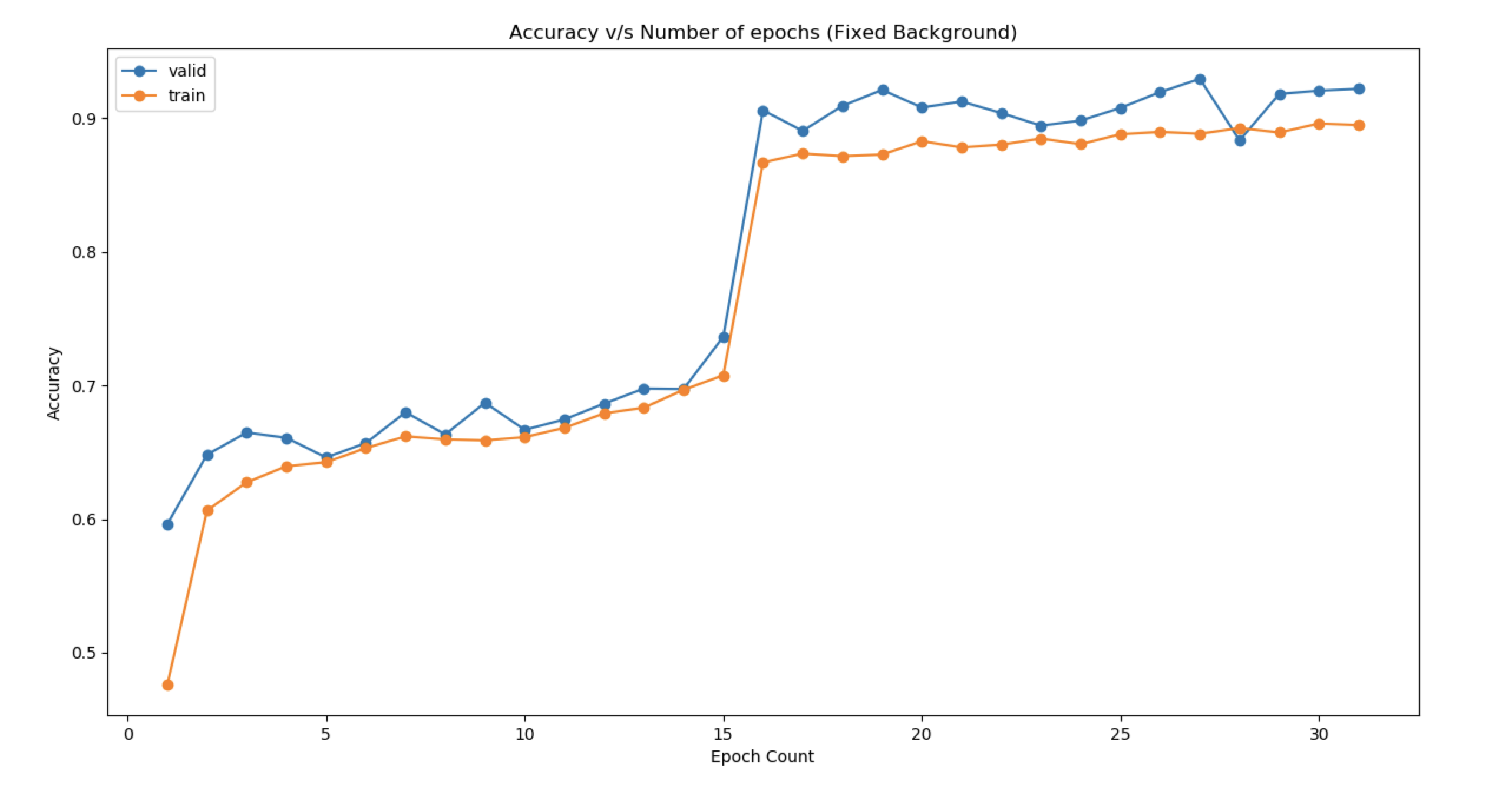
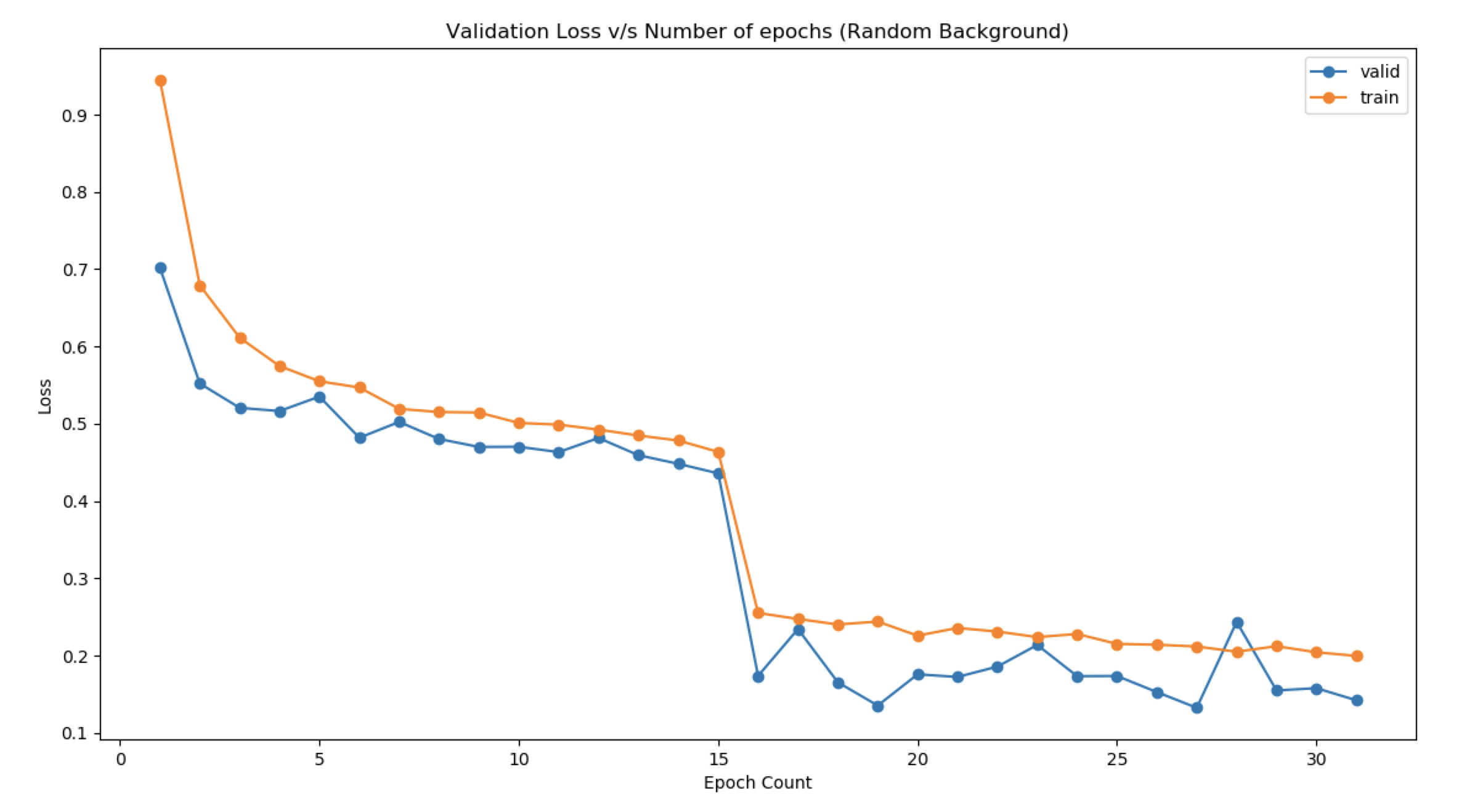
- Choice of Hyperparameters: Kernel size kept small (3,3) to learn more low-level features while keeping the size of the image the same so that more convolutions can be carried out in the future. Gradually the number of kernels has been increased after successive pooling and dropouts. This ensures that the model learns more high-level features. Dropout has been kept to prevent the model from overfitting. It is kept at 0.2 at the end of the model, while batch normalization ensures that the gradients are getting normalized after each layer. Glorot Normal initialization has been used.
- Increase the number of epochs until the validation accuracy starts decreasing even when training accuracy is increasing(overfitting).
- Softmax is used in the output layer while making multi-class predictions.
- Ideally, it may be better to use different weight initialization schemes according to the activation function used on each layer.
- Fixed Background
- Generic Background
- Choice of Hyperparameters: Kernel size kept small (3,3) to learn more low-level features while keeping the size of the image the same so that more convolutions can be carried out in the future. Gradually the number of kernels has been increased after successive pooling and dropouts. This ensures that the model learns more high-level features. Dropout has been kept to prevent the model from overfitting. It is kept at 0.2 at the end of the model, while batch normalization ensures that the gradients are getting normalized after each layer. Glorot Normal initialization has been used.
-
Live Demo
- Fixed Background
- Generic Background
- Fixed Background